soundstream-light
Contents
SoundStream是Google提出的端到端神经音频压缩模型,能够以低码率获得高保真重建,适用于实时语音、在线会议与多媒体应用。我将精简的C++推理实现与官方TFLite模型整合,打包成Python模块和跨平台命令行工具。
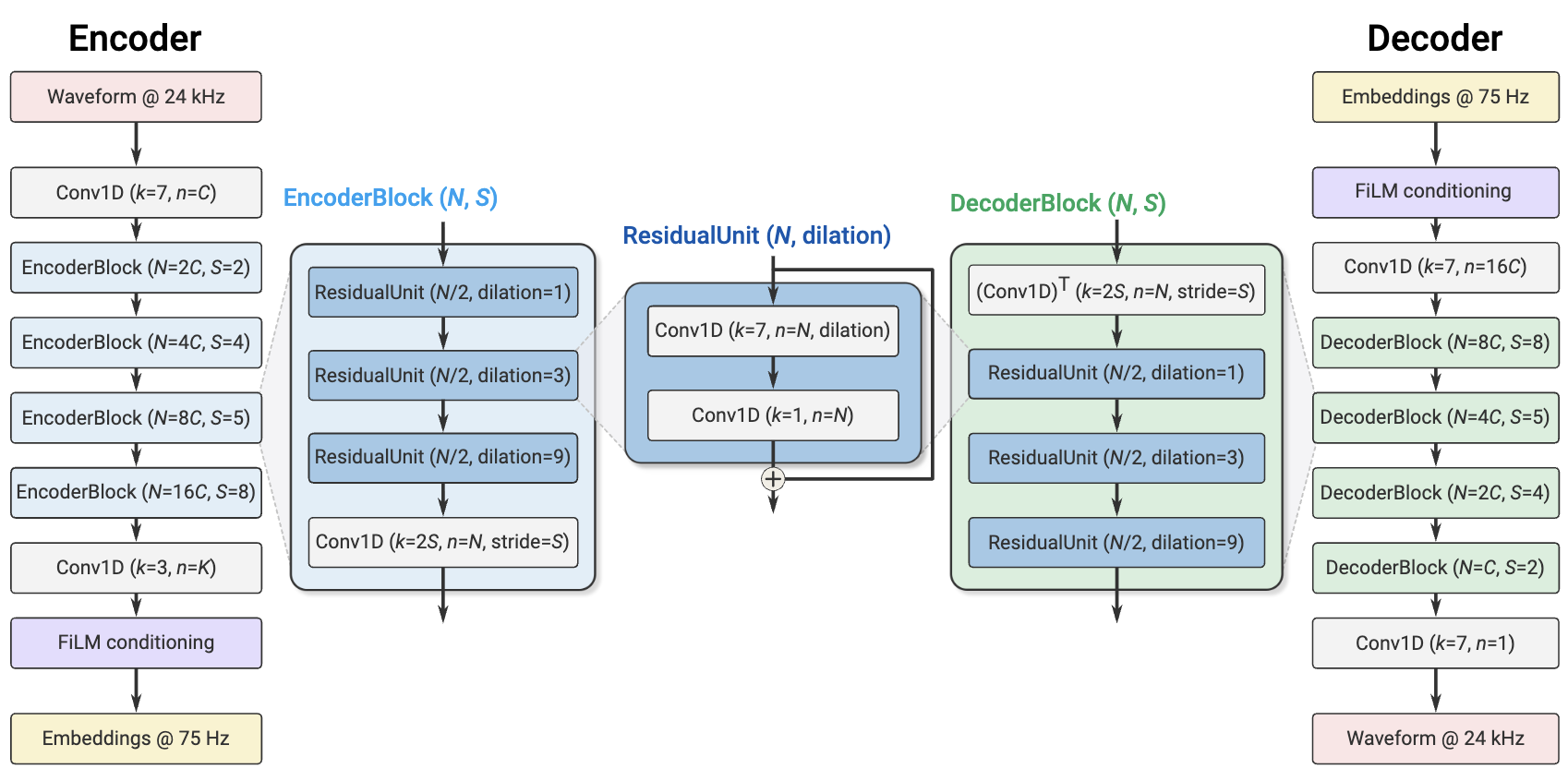
具体用法 #
使用uv安装,
shell
uv pip install git+https://github.com/binbinsh/soundstream-light.git下载模型:
shell
uv run soundstream-cli models fetch在python中调用模型:
python
from scipy.io import wavfile
import numpy as np
from soundstream_light import encode, decode
rate, pcm = wavfile.read("test.wav")
waveform = pcm.astype(np.float32) / 32768.0
embeddings, meta = encode(waveform)
recon = decode(embeddings, metadata=meta)
wavfile.write(“test_recon.wav", rate, (np.clip(recon, -1.0, 1.0) * 32768.0).astype(np.int16))使用命令行运行模型:
shell
uv run soundstream-cli encode test.wav test.embeddings
uv run soundstream-cli decode test.embeddings test_recon.wav默认模型路径为 ./models,可用环境变量 SOUNDSTREAM_MODELS_DIR 自定义。