Wrap the SoundStream TFLite model into a Python library
I created an open‑source project soundstream-light, which integrates a lightweight C++ inference implementation with the official TFLite model, and packages it as a Python module and a cross‑platform command‑line tool.
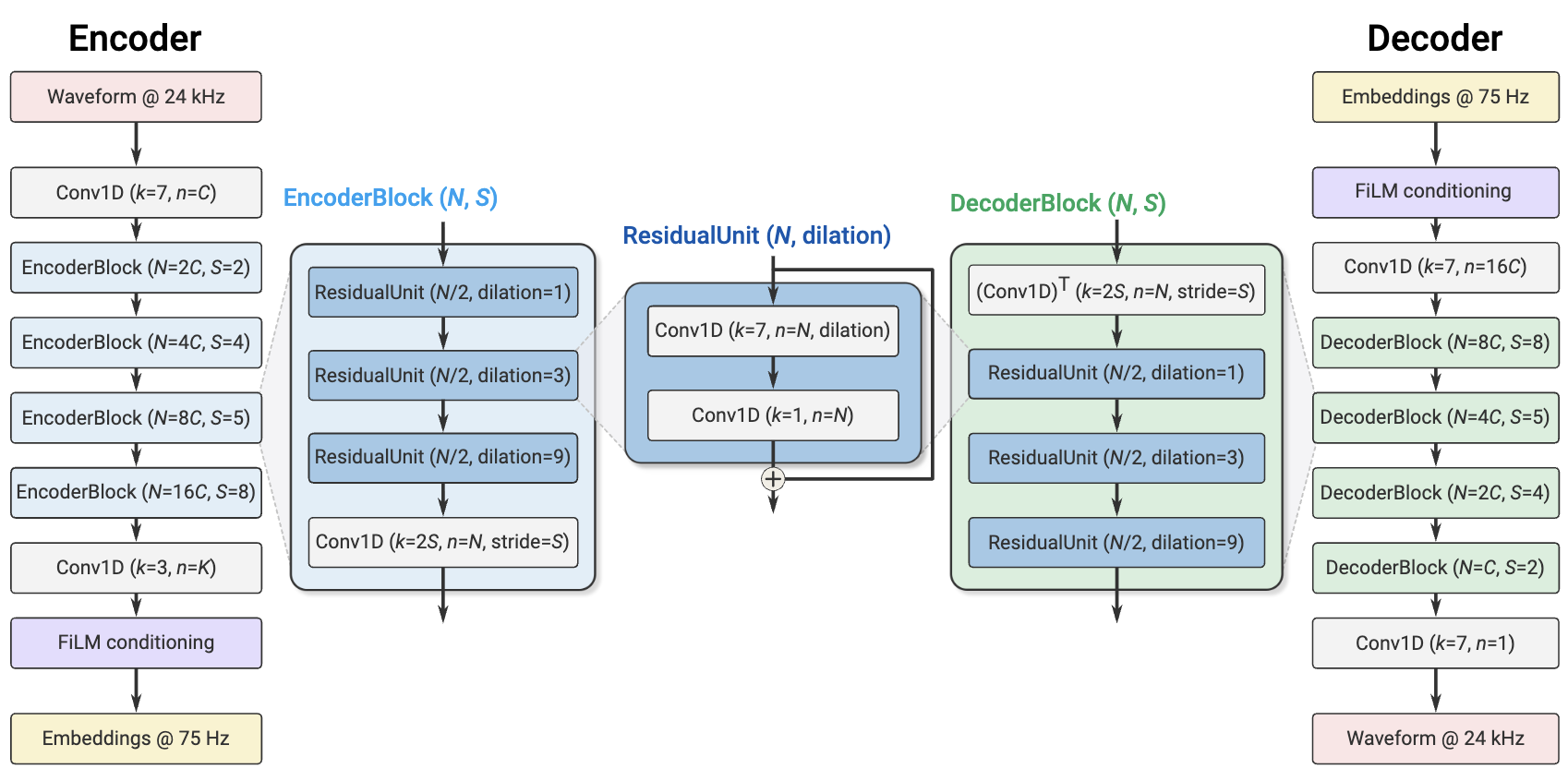
SoundStream is an end‑to‑end neural audio compression model proposed by Google, capable of achieving high‑fidelity reconstruction at low bitrates, suitable for real‑time speech, online meetings, and multimedia applications.
Specific Usage
Install from PyPI using uv,
uv pip install soundstream-lightDownload the model:
uv run soundstream-cli models fetchCall the model in Python:
from scipy.io import wavfile
import numpy as np
from soundstream_light import encode, decode
rate, pcm = wavfile.read("test.wav")
waveform = pcm.astype(np.float32) / 32768.0
embeddings, meta = encode(waveform)
recon = decode(embeddings, metadata=meta)
wavfile.write("test_recon.wav", rate, (np.clip(recon, -1.0, 1.0) * 32768.0).astype(np.int16))Run the model via the command line:
uv run soundstream-cli encode test.wav test.embeddings
uv run soundstream-cli decode test.embeddings test_recon.wavThe default model path is ./models; you can customize it with the environment variable SOUNDSTREAM_MODELS_DIR.
The source code of this open‑source project is at https://github.com/binbinsh/soundstream-light/.